When localization works wrong in UE
I definitely think that my future self will stumble here again. So I leave a note.
Check Need Review: If something is invisible or is displayed wrong
If you don’t see the item, make sure it isn’t in Needs Review. This function may be essential when multiple people are working, but in my case, it was a cause that made me wander into the wrong place several times.
Debugging may be faster
Debugging may be faster than searching documents or posts.
Localization is worked in several stages. And many elements look similar but are subtly different. Even Unreal Engine’s localization-related features appear to have been frequently modified. This means: Unreal Engine localization is very difficult to document. Because of this, resources available on the web about localization tasks often do not provide detailed or in-depth coverage. Additionally, there may be cases where it does not reflect the latest state.
Where engine loads localized data
FLocalizationResourceTextSource::LoadLocalizedResources() :
GitHub Link
What struck me was that the folder name was hard-coded. But if we think about it, the Contents folder name is also hard coded.
A note about commandlet debugging related to Count Words behavior issues
The options I used are below.
-run=GatherText -config="Config/Localization/LocalizationTargetName_GenerateReports.ini"
The locations of the important breakpoints I want to record are as follows:
FLocTextHelper::GetWordCountReport(): Where words are counted GitHub LinkUGatherTextCommandlet::ProcessGatherConfig(): Where commandlet begins to work GitHub Link
Localization of the string table and a dummy culture
This forum post was impressive.
How to localize your game using String Tables
The text before and after the translation of native culture must be the same
If these are different, word counting will be incorrect. I will discuss this in detail in separate post. Please note that in this case, the translated text is displayed fine, so it is not easy to figure out where the mistake is.
The workflow of the localization and steps of making intermediate resources
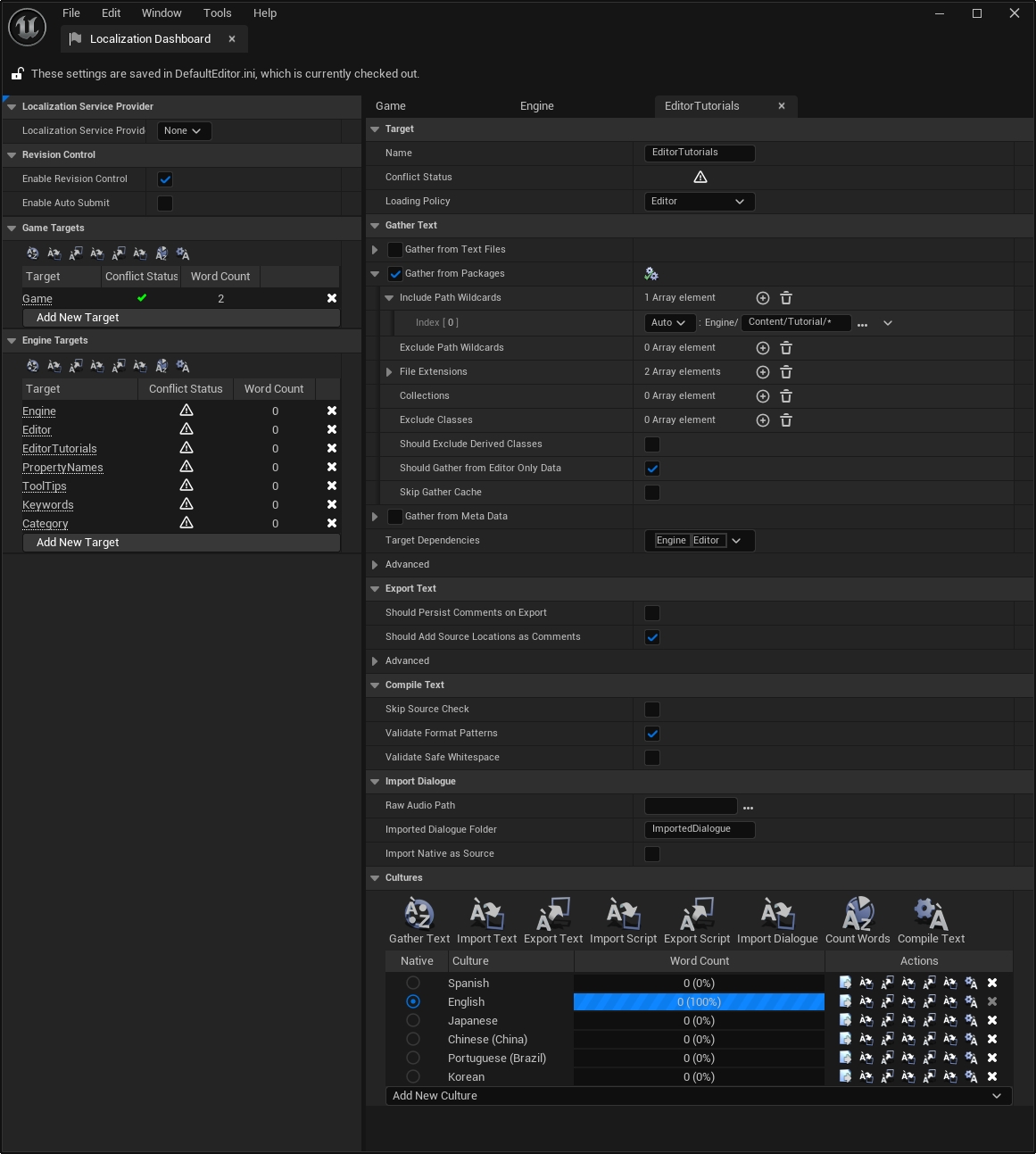
Let’s assume that the target name is ExampleTargetName and the cultures of en-US-POSIX, ko, and jp are used. Please refer to the forum post mentioned above about the identity and purpose of en-US-POSIX. I think that you can know what the target name is by looking at the localization dashboard screenshot above.
When we make localization-related settings like the above and collect text, the collected content is saved like below.
The collected words are saved in the manifest file, and based on this, the value of the text before translation is filled in the archive file of each culture folder.
Exceptionally, in the case of native culture, the same content is filled in the text before translation and text after translation.
Typically, this will be where we fill in the texts after translation (in this case ko and jp) and then compile the texts to create the final localization data.
If we proceed to this point, it will look like this: